How to write scientific documents
Premise # ↰
Here I am giving my personal advices, based on my personal experience; I am not listing a set of rules. However, I do believe that many of these advices can be intended as guidelines and are widely accepted.
I thank all the colleagues (namely, Alberto) and PhD students (namely, Giorgia, Marco, Jessica) who helped me refining these guidelines in years of writing.
Document structure and language # ↰
Here I refer specifically to computer science scientific articles and namely to those presenting experimental results.
Abstract # ↰
A good abstract usually follows this general structure.
- One or two sentences presenting the general context (e.g., robotics).
- One or two sentences presenting the more specific context (e.g., design of controllers for modular robots).
- One sentence, possibly bold, saying what is the current gap, problem, or limitation.
- A few sentences introducing the proposal of the paper, clearly connecting them to the gap/problem/limitation of the previous sentence. This part of the abstract usually starts with In this paper, we propose….
- One or two sentences mentioning the experimental evaluation of the proposal, possibly detailing (briefly!) the peculiarities of the experiments and anticipating the salient results.
- Optionally (but nice to have!) one sentence attempting to summarize the broader impact of the research, beyond the specific context.
Example 1 # ↰
From this paper.
(general context →) Graphs are a way to describe complex entities and their relations that apply to many practically relevant domains. (specific context →) However, domains often differ not only in the properties of nodes and edges, but also in the constraints imposed to the overall structure. (limitation →) This makes hard to define a general representation and genetic operators for graphs that permit the evolutionary optimization over many domains. (proposal →) In this paper, we tackle this challenge. We first propose a representation template that can be customized by users for specific domains: the constraints and the genetic operators are given in Prolog, a declarative programming language for operating with logic. Then, we define an adaptive evolutionary algorithm that can work with a large number of genetic operators by modifying their usage probability during the evolution: in this way, we relieve the user from the burden of selecting in advance only operators that are “good enough”. (experimental evaluation →) We experimentally evaluate our proposal on two radically different domains to demonstrate its applicability and effectiveness: symbolic regression with trees and text extraction with finite-state automata. The results are promising: our approach does not trade effectiveness for versatility and is not worse than other domain-tailored approaches.
Example 2 # ↰
Form this paper.
(general context →) The recent and rapid progresses in Machine Learning (ML) tools and methodologies paved the way for an accessible market of ML services. (specific context →) In principle, small and medium-sized enterprises, as well as big companies, could act as providers and consumers of services, resulting in an intense exchange of ML services where a consumer may ask many providers for a service preview based on its particular business case, that is, its data. (limitation →) In practice, however, many potential service consumers are reluctant to release their data, when seeking for ML services, because of privacy or intellectual property concerns. As a consequence, the market of ML services is not as fluid as it could be. An alternative to providing real data when looking for an ML service consists in generating and releasing synthetic data. The synthetic data should (a) allow the service provider to preview an ML service whose performance is predictive of the one the same service will achieve on the real data and (b) prevent the disclosure of the real data. (proposal →) In this paper, we propose a data synthesis technique tailored to a family of very relevant business cases: supervised and unsupervised learning on single-table datasets and relational datasets. Our technique is based on generative deep learning models and we instantiate it in three variants: standard Variational Autoencoders (VAEs), beta-VAEs, and Introspective VAEs. (experimental evaluation →) We experimentally evaluate the two variants to measure the degree to which they meet the two requirements above, using several performance indexes that capture different aspects of the quality of the generated data. (broader impact →) The results suggest that data synthesis is a practical answer to the need of decoupling ML service providers and consumers and, hence, can favor the arising of an active and accessible market of ML services.
Example 3 # ↰
From this paper.
(general context →) Modular robots are promising for their versatility and large design freedom. (specific context →) Modularity can also enable automatic assembly and reconfiguration, be it autonomous or via external machinery. (limitation →) However, these procedures are error-prone and often result in misassemblings. This, in turn, can cause catastrophic effects on the robot functionality, as the controller deployed in each module is optimized for a different robot shape than the actual one. (proposal →) In this work, we address such shortcoming by proposing a shape-aware modular controller, operating with (1) a self-discovery phase, in which each module controller identifies the shape it is assembled in, followed by (2) a parameter selection phase, where the controller selects its parameters according to the inferred shape. We deploy a self-classifying neural cellular automaton for phase (1), and we leverage evolutionary optimization for implementing a library of controller parameters for phase (2). (experimental evaluation →) We test the validity of the proposed method considering voxel-based soft robots, a class of modular soft robots, and the task of locomotion. Our findings confirm the effectiveness of such a controller paradigm, and also show that it can be used to partially overcome unforeseen damages or assembly mistakes.
Tenses and sections # ↰
A common practice is to use:
- present tense in the Abstract and Introduction section: We propose…, Current techniques have this limitation
- past tense in the Related works section: Smith et al. proposed…, Previous works showed that…
- present tense in the section where you formalize the problem (might be named Problem statement) and the one where you describe your proposal (might be named Our approach): Let $x$ be…, We repeate the following procedure $n$ times…
- past tense and present tense in the Experimental evaluation section, past in the part where you describe what you did, present where you comment the results: We considered four datasets…, We repeated the learning three times…, Figure 3 shows the results of…, We explain this gap in performance with…
- past tense in the Conluding remarks section, with the exception of a possible paragraph about future work where, obviously, we should use the future tense: We considered the problem of…, We showed that…, We will extend the approach to…
Language # ↰
Active voice # ↰
Use active voice! This is a very strong recommendation. Active voice makes clear who is the actor/author of, and hence who has the responsability for, an action/claim/consideration. In most of the cases, that means writing we did something, because the main responsability for all the claims in a paper is in charge of the authors. When describing a procedure or an algorithm, the subject might be the procedure or algorithm: The algorithm works as follows: it initializes a set of…, it selects one…. When describing the work of others (i.e., in the Related works section), use them as subject: Smith et al. showed that….
Contracted forms # ↰
Do not use contracted forms such as can’t or isn’t. They are more suitable for informal communication than for technical writing. Moreover, the efficiency increase (in terms of information given in the unit of space, here characters) is not that large.
There are some peculiar (but common in scientific text) expressions whose contracted form is tolerated, namely, w.r.t. for with respect to and approx. for approximately. Personally, I prefer the extended form also in these cases. (If you use them, pay attention to spacing).
Acronyms # ↰
Use acronyms for terms, in particolar for technical ones (e.g., false positive rate (FPR), genetic programming (GP), …), that you mention more than once in the document.
The general rule is to introduce both the expanded and the contracted form at the first occurrence of the term and then use always the contracted form. There are, however, a few exception to this general rule.
- If you use the term only once in the abstract, you can defer the introduction of the contracted to a later stage.
- Possibly re-introduce both forms after the abstract.
- Possibly re-introduce both forms, or use just the expanded form, in the conclusions.
- Show both forms if the term is the title of a section.
Be consistent: capitalize all or none of the expanded forms: e.g., Genetic Programming (GP) and False Positive Rate (FPR), or genetic programming (GP) and false positive rate (FPR); obviously, some terms are capitalized by their own (e.g., Smith’s sorting algorithm (SSA)), so keep the correct capitalization.
Moreover:
- if appropriate, use the plural form also for the contracted form, e.g., once you introduced the evolutionary algorithm (EA), you may write we compared five EAs.
- use proper articles before acronyms, i.e., those that you would put if you pronounced the contracted forms, e.g., an MLP.
Managing acronyms looks an hard thing, but fortunately there are LaTeX packages that do most of the work.
British vs. American English # ↰
There are slightly differences between British and American English, e.g., colour vs. color, behaviour vs. behavior, focussed vs. focused. I personally prefer American English. The important thing is to be consistent: so choose your preferred variant and keep it trhoughout the entire document. (However, consider that if it’s a paper and I am a co-author, I will reserve the right to argue a bit for supporting my preference over your preference).
Possessive case (’s or not ’s?) # ↰
This is a particularly mild advice, since I do not feel confident enough on this matter to be authoritative.
That said, as far as I know, ’s should be reserved to people (both proper and common names), physical places (cities, countries), and a few other things (e.g., today’s meeting). In practice, few of these things are relevant in a scientific article or technical document, the most common one being the user. So write the user’s choice, but don’t write the algorithm’s complexity; write just the algorithm complexity.
Typography # ↰
Plain text # ↰
I.e. and e.g. # ↰
Use i.e. (that stays for id est, for explaining something, also doable with a that is) and e.g. (for giving one or more examples) always with a comma before and after: we increase $i$, i.e., the counter…, there can be special cases, e.g., a division by zero.
Dashes # ↰
Use proper dashes in text:
- - (hyphen or just dash,
-in LaTeX) for composed words, without spaces before and after; if you use two similar composed works close to each other, you can shorten one: we tested an MLP- and a random-based controller… - – (en-dash,
--in LaTeX) without spaces before and after for ranges (but prefer managing ranges with packages) - — (em-dash,
---in LaTeX) without spaces before and after for expressing a parenthetical thought, i.e., a bit of information, maybe giving more details, or an aside, that might be showed between parentheses: we tested this approach with an MLP—we also experimented with other kinds of controller with no qualitative different findings.
Oxford comma # ↰
Use Oxford comma (also known as serial comma), i.e., a comma before the and (or the or) coming before the last item of a list including more than two items: we experimented with multi-layer perceptrons, recurrent neural networks, and a random controller. This is a pretty subjective recommendation (I use it with pleasure), but I think it is also pretty widely accepted and well motivated.
Ordinal numbers # ↰
Use a consistent form for ordinal numbers.
I personally prefer the $i$-th form ($i$-th in LaTeX) because it’s more readable, when in plan text, than the superscript version $i$th.
Note that this form for ordinal numbers should be used parsimonously: when you just have few ordinals, write the extended form, i.e., first, second, …
Versus # ↰
In English, there is a dot after vs., e.g., single- vs. multi-core execution. Put it.
Mathematical notation # ↰
This is about the choices you do when defining the mathematical notation for the entities you are going to write about in your document.
Premise 1. Choosing the mathematical notation for an entity is like choosing the name of a variable/type/method/… in a piece of code: choosing the right name is often half of the modeling job. So it’s much more than just typography.
Premise 2. There are specific praxes and expectations in some scientific communities. If possible, try to conform to those praxes if your document will be consumed by people belonging to a community.
Single-letter entities # ↰
Try (hardly!) not to use more than one letter for math entities. If you have one single parameter concerning the size of something, it could be an $n$; if you have two of them, they could be $n$ and $m$. If you have several of them, use subscripts: e.g., use $n_\text{pop}$, $n_\text{gen}$, $n_\text{tourn}$ not $\text{pop}$, $\text{gen}$, $\text{tourn}$ (and neither $pop$, $gen$, $tourn$), for the size of the population.
Lowercase and uppercase letters # ↰
If possible, use uppercase letters for entities representing collections of items, such as sets and bags: $a \in A$.
An exception to this rule is given by vectors (see below).
If you need to define collections of collections, maybe use calligraphy (\mathcal{} in LaTeX) uppercase letters, e.g., given a set $\mathcal{A}=\{A_1, A_2, \dots\}$ of bags, where each bag $A_i$ contains….
Vectors # ↰
(This is a matter of personal tastes, actually…) For vectors, or, more broadly, for sequences of items of the same type, use bold: $\boldsymbol{x} = (x_1,x_2,x_3,x_4) \in \mathbb{R}^4$. Bold is lighter than an arrow above the letter, in particular when there are superscripts: $\boldsymbol{x}^{(i)}$ vs. $\vec{x}^{(i)}$. Possibly extend this notation to matrices: $\boldsymbol{a} \in \mathbb{R}^{n \times m}$ or $\boldsymbol{A} \in \mathbb{R}^{n \times m}$.
For using bold in math environment in LaTeX, I usually (re)define an ad hoc macro (with \renewcommand\vec{\boldsymbol}) that can be used as \vec{x}.
Delimiters for pairs, tuples, sequences # ↰
Use round parentheses for detailing the content of pairs and tuples, both in extended form ($p = (a,b)$) and in compact form ($\boldsymbol{s} = (s_i)_i$ or $D_\text{learn}=\{(x^{(i)},y^{(i)})\}_i$).
For numerical vectors, square brackets are ok too. But they are particularly ok for denoting the concatenation of vectors: $\boldsymbol{x} = [\boldsymbol{x}_\text{train} \; \boldsymbol{x}_\text{test}]$.
Functions signature and mapping # ↰
Use an arrow ($\to$, \to in LaTeX) for defining the signature of a function ($f: \mathbb{R} \to [0,1]$) and $\mapsto$ (\mapsto in LaTeX) for showing the concrete way a function works: $x \mapsto \min(x^2, 1)$.
The latter is in facts much more commonly shown as $f(x)=\min(x^2, 1)$.
LaTeX # ↰
General # ↰
Ellipses # ↰
Use \dots, not a literal ..., for ellipses, both in text and in a math environment: \vec{x} = (x_1, \dots, x_n).
Paragraphs # ↰
Use an empty line in the source for a new paragraph (not \\ or \newline!).
Only when really necessary (which happens very rarely), use \\ for starting a new line in the text.
Double quotes # ↰
Typeset double quotes with ``something’’ (that will be rendered properly, $\text{“something”}$).
Emphasis # ↰
Use \emph{}, not \textit{}, for emphasizing text.
Why? Because \emph{} suggests already in the source what’s the semantics, i.e., the role, of the enclosed piece of text, while \textit{} is a rendering hint.
That said, unfortunately, LaTeX is not a good language for separating the document structure from hints on how to render it.
You should emphasize key terms, commonly just at the first occurrence.
Controlled or unbreakable spaces # ↰
In documents rendered by LaTeX, there is usually a longer space after a fullstop in plain text, because this improves readability.
However, there are cases where a dot does not actually play the role of a fullstop.
In those cases, use a controlled space (\ ): e.g., I thank prof.\ Smith, single- vs.\ multi-core processing.
In many cases you do not want to let LaTeX split a line between two things that should not be separated.
In those cases, use an unbreakable space (~): e.g., \cite{medvet2018writing}~suggests that (when using short citation formats, rendered as [1] or similar), or P.~Smith suggest that.
Mathematical notation # ↰
Provided that you should avoid multi-letter names for entities, whenever you put words in math environment, enclose them in \text{}, e.g., \text{FPR}=0.85, \rho_\text{NN}, n_\text{pop}.
When you don’t follow this advice, the text is rendered in a way (through spacing) that suggests that there is a product of things, rather than a single entity: $1-\text{FPR}$ vs. $1-FPR$, $n_\text{pop}$ vs. $n_{pop}$.
Brackets size # ↰
Use \left and \right before brackets (of any type) when you want them to be large enough with respect to the the enclosed content.
The difference in rendering can be more or less apparent depending on the context (inline or not) of the math environment.
E.g., (\frac{1}{n}) is $(\frac{1}{n})$, whereas is \left(\frac{1}{n}\right) is $\left(\frac{1}{n}\right)$.
For the definition of different cases in a math environment, use \begin{cases} and \end{cases}, which will be rendered with a big brace.
Max, argmax # ↰
For max and min there are suitable ad hoc macros: \max_i x_i.
So don’t simply write max, which would be badly rendered: $max(1,x)$ vs. $\max(1,x)$.
For argmax and argmin, you can define your own macro.
Mine is \DeclareMathOperator*{\argmax}{\arg\,max}.
The \, puts a nice short space between arg and max.
Useful packages # ↰
Fundamental premise. LaTeX is very old. And writing scientific text is a practice that is even older. Hence it is very unlikely that you are the first one who faces one specific problem, e.g., how to nicely format a table or how to properly put the name of authors of referenced papers. So, whenever you think that your rendered document does not look as nice as you want, look for someone (usually on stackoverflow) who already solved the problem of making it nicer. If instead you don’t see that your document is not as nice as it should be, look at other nicer documents!
Quantities with siunitx
#
↰
This package is mainly for dealing with quantities and units of measure.
Use it for raw numbers (i.e., raw quantities, usually not for years and dates) in text (we performed this procedure \num{30} times) and also in math environment with big numbers ($x=\num{10000}$ or there are more than \num{25000} observations).
In the latter case, siunitx will put a short space as a thousands separator, greatly improving the readability: $10\,000$ vs. $10000$.
Use it for quantities with measure, wherever appropriate: the experiment lasted more than \qty{35}{\second}, we used a machine with \qty{16}{\giga\byte} RAM.
Use it for ranges and lists: runs took \qtyrange{10}{25}{\minute}, we experimented with \numlist{1;10;15;25} moves for each user.
The package can be configured to use Oxford comma for lists, with \sisetup{list-final-separator = {, and }}.
siunitx is also very handy for formatting tables, in particular for aligning numbers in columns where numbers have some decimals, possibly not the same number of decimals.
E.g., S[table-format=3.2] defines a column format where the numbers are horizontally aligned in order to have the decimal separator always at the same place, with enough space for 3 digits on the left and 2 on the right (after the separator).
Acronyms with glossaries
#
↰
Once you defined your acronyms, glossaries manages automatically the choice of the form to be used (extended or contracted).
You define an acronym with \newacronym{ea}{EA}{evolutionary algorithm} (usually at the beginning of the source) and then use it with \gls{ea}: the package will render the extended form at the first occurrence and the contracted form at later ones.
You can show the plural form with \glspl{}, or a capitalized form with \Gls{}, or many other variants.
If you use the hyperref package (which I recommend), it’s handy to disable the hyperlinks for acronyms, with \glsdisablehyper.
You can reset the memory of first usage flags (e.g., just after the abstract), with \glsresetall.
References with cleveref
#
↰
With cleveref you can have references to other parts of the document which are consistent in the way they are rendered.
Instead of writing see Figure~\ref{fig:results-lineplots} (that maybe you write as, inconsistenly, in Fig.~\ref{fig:results-boxplots} elsewhere in the document), you can simply write see \Cref{fig:results-lineplots}.
The package will render the proper word depending on what you are referring to (e.g., Section, Table, Figure, …).
Moreover, the package will render nicely multiple references: See \Cref{fig:results-lineplots,fig:results-boxplots} will be rendered as See Figures 2 and 3.
You can also use the non-capitalized version of the reference with \cref{}, but do it consistently.
Tables with booktables
#
↰
In general, in tables use horizontal rules parsimonously and do not use vertical rules.
booktables facilitates this with a few macros: \toprule, \midrule, \bottomrule, \cmidrule.
In particular, you can use \cmidrule to group columns together and \midrule to separate horizontal sections of the paper.
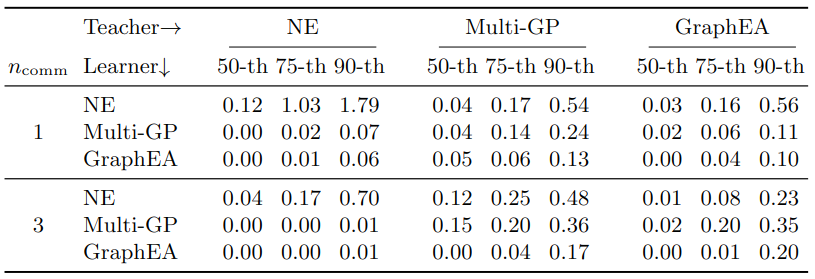
An example from this paper:
\begin{tabular}{
c @{\hspace{2mm}}
l @{\hspace{5mm}}
S[table-format=1.2] @{\hspace{1mm}}
S[table-format=1.2] @{\hspace{1mm}}
S[table-format=1.2]
c @{\hspace{5mm}}
S[table-format=1.2] @{\hspace{1mm}}
S[table-format=1.2] @{\hspace{1mm}}
S[table-format=1.2]
c @{\hspace{5mm}}
S[table-format=1.2] @{\hspace{1mm}}
S[table-format=1.2] @{\hspace{1mm}}
S[table-format=1.2]
}
\toprule
& Teacher$\rightarrow$ & \multicolumn{3}{c}{NE} & & \multicolumn{3}{c}{Multi-GP} & & \multicolumn{3}{c}{GraphEA} \\
\cmidrule(lr){3-5} \cmidrule(lr){7-9} \cmidrule(lr){11-13}
$n_\text{comm}$ & Learner$\downarrow$ & {\num{50}-th} & {\num{75}-th} & {\num{90}-th} & & {\num{50}-th} & {\num{75}-th} & {\num{90}-th} & & {\num{50}-th} & {\num{75}-th} & {\num{90}-th} \\
\midrule
\multirow{3}{*}{\num{1}}
& NE & 0.12 & 1.03 & 1.79 & & 0.04 & 0.17 & 0.54 & & 0.03 & 0.16 & 0.56 \\
& Multi-GP & 0.00 & 0.02 & 0.07 & & 0.04 & 0.14 & 0.24 & & 0.02 & 0.06 & 0.11 \\
& GraphEA & 0.00 & 0.01 & 0.06 & & 0.05 & 0.06 & 0.13 & & 0.00 & 0.04 & 0.10 \\
\midrule
\multirow{3}{*}{\num{3}}
& NE & 0.04 & 0.17 & 0.70 & & 0.12 & 0.25 & 0.48 & & 0.01 & 0.08 & 0.23 \\
& Multi-GP & 0.00 & 0.00 & 0.01 & & 0.15 & 0.20 & 0.36 & & 0.02 & 0.20 & 0.35 \\
& GraphEA & 0.00 & 0.00 & 0.01 & & 0.00 & 0.04 & 0.17 & & 0.00 & 0.01 & 0.20 \\
\bottomrule
\end{tabular}
which is rendered as:
Plots with pgfplots
#
↰
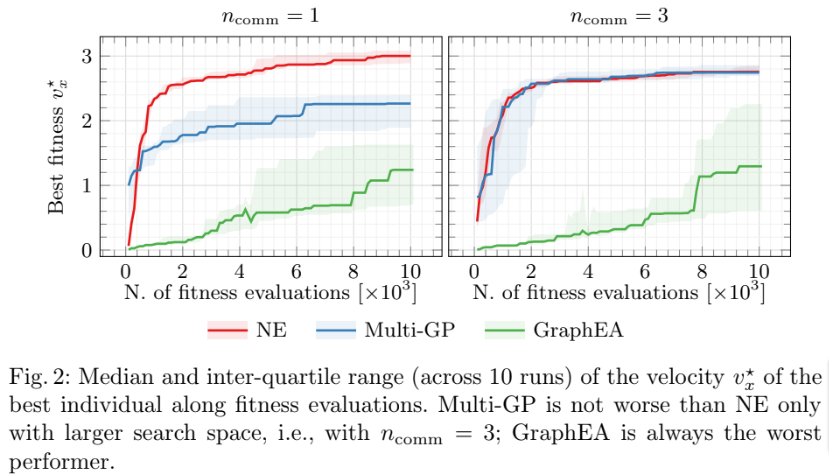
Plots are a very powerful way to deliver information, in particular to communicate the salient results of the experimental analysis in a space-efficient way. However, choosing the appropriate plot is not trivial, regardless of the tool you use for building the plot.
If you want to put plots in your document and you authored it with LaTex, pgfplots will help you render plots that nicely match the style of everything else in the document (namely, the font and text size).
Unfortunately, mastering this tool takes time, practice, and experience.
Here I show an example from this paper:
References with natbib
#
↰
The format of citations in the text and of references in the References section is almost always dictated by the template of the document. And it’s a good thing to not try to subvert that format.
However, there are a few practices of citations for which natbib is useful, the main one being when you name the authors of the cited paper: \citet{smith19cost} showed that the cost might be rendered, depending on the format, as Smith et al. [32] showed that the cost.
The Overleaf website shows some tips for using LaTex, including some suggesting how to use natbib for citation styles.
Lists with enumitem
#
↰
When describing complex procedures, explicitly marking steps can improve the readability of the text: e.g., We proceed as follows: (i) we compute the initial value, (ii) we increase it…. Similarly, there are short lists for which you want to highlight the items, just because they are important: e.g., Our algorithm meets the two aforementioned requirements, because (a) it always produces a valid solution and (b) it does not require….
Instead of manually writing (i), (ii), … in LaTeX, you can use the enumitem package with the inline option, i.e., loading it with \usepackage[inline]{enumitem}.
Moreover, you can explicitly reference items in the lists, provided you labeled them with \label{}.
An example:
Then, it iteratively modifies $p$ according to these three steps:
\begin{enumerate*}[label=(\roman*)]
\item \label{item:alg-desc-find} it finds all the cells in $p$ that are labeled with a non-terminal symbols in $N$, i.e., those which can be replaced according to a rule in $\mathcal{R}$;
\item \label{item:alg-desc-choose-cell} it chooses one cell $(x^\star,y^\star)$ to be the target of the replacement using the sorting criterion $c$;
\item \label{item:alg-desc-choose-rule} it chooses, based on the genotype $g$ and the state $s$ (initialized to $\varnothing$), one rule to apply among the ones suitable for the cell at $(x^\star,y^\star)$;
\item \label{item:alg-desc-replace} finally, if possible, it performs the replacement in $p$ according to the chosen rule.
\end{enumerate*}
Step~\ref{item:alg-desc-choose-rule} is the main contribution of this work.
which will be rendered as:

Style of LaTeX source code # ↰
There are a few things you can do to make the source LaTeX code of your document more readable.
- Indent your code.
- Put three blank lines before every section (that is,
\section{},\subsection{}, …,\paragraph{}). - Put one sentence per line in the source code: this makes easier to find the place in the source code which corresponds to a given sentence in the rendered document, by looking at the start of the sentence. Moreover, this easies the management of the document with versioning tools (also those that are included in the LaTeX IDEs, like Overleaf).
- Don’t define LaTeX macros for comments. Either use plain LaTeX comments in the source
% here is a commentor, for comments which are functional to the collaborative editing of the document, use the commenting feature of the IDE, namely, of Overleaf.